Lets now take a look at how the serial implementation for channel solvers was replaced with a parallel one. This is just a first attempt at parallelization, and there are a number of ways in which the algorithm can be tweaked to improve performance.
First, we need a good understanding of the serial implementation. What happens in the channel solver is very simple. Here is the equation (I've skipped out the derivation of this equation, but you can look it up elsewhere):
First, we need a good understanding of the serial implementation. What happens in the channel solver is very simple. Here is the equation (I've skipped out the derivation of this equation, but you can look it up elsewhere):
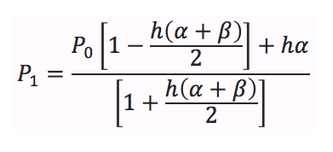
P0 is the current state of the channel and P1 is it's new state. h is the small time increment over which the state changes from P0 to P1. Alpha and Beta are the rates of opening and closing of the channels.
Solving this equation for each of the channels in each of the compartments is all that happens in the channel calculations. Alpha and beta change based on the current voltage of the cell. MOOSE takes care of this by maintaining a lookup table in which different values of voltage V map to unique values of alpha and beta. So before this calculation is performed, the lookup table is referred to get the values at the current voltage of the cell. There are multiple types of channels, each of which have their own unique values for a and b for each voltage. So there are multiple lookup tables - one for each type of channel.
This is how the serial algorithm works:
Solving this equation for each of the channels in each of the compartments is all that happens in the channel calculations. Alpha and beta change based on the current voltage of the cell. MOOSE takes care of this by maintaining a lookup table in which different values of voltage V map to unique values of alpha and beta. So before this calculation is performed, the lookup table is referred to get the values at the current voltage of the cell. There are multiple types of channels, each of which have their own unique values for a and b for each voltage. So there are multiple lookup tables - one for each type of channel.
This is how the serial algorithm works:
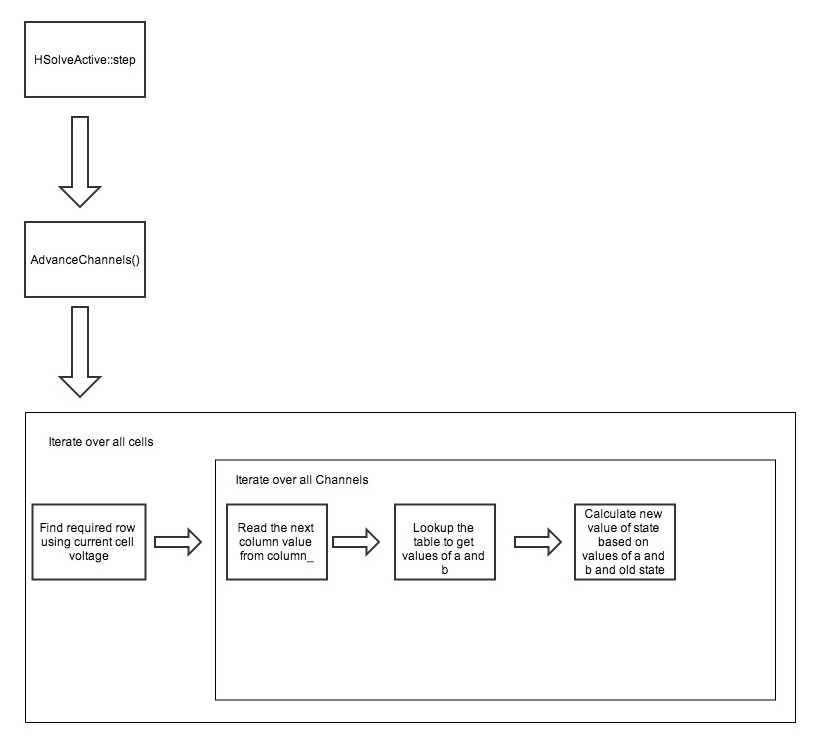
So for each channel of each compartment, the row to be looked up is found using the voltage, while the column is decided based on the type of channel. This is done during initialization and stored in a array, so it only needs to be read sequentially here.
The key point to be made here is that all of the calculations for each of the channels happens completely independently of the other channels in both the same cell and other cells. Each of these calculations can be done in parallel.
The key point to be made here is that all of the calculations for each of the channels happens completely independently of the other channels in both the same cell and other cells. Each of these calculations can be done in parallel.
Parallelizing Channel Calculations
It might seem pretty straightforward to parallelize this calculation - Just calculate one channel on one node of the GPU. And theoretically, that's all needs to be done. But there are a few complications that need to be addressed. Firstly, in calculations like this, the actual arithmetic operations usually take only a small portion of time. The majority of the time is spent just transferring the data onto the GPU memory before the calcualtions and back. So this memory transfer has to be optimized as much as possible for the parallelization to have any effect on processing time. The way that I implemented this is to generate arrays of all the input voltages and channel types. The arrays is filled up sequentially with the current voltage values and then transferred to GPU memory. The GPU then performs the lookup and arithmetic operations in parallel on each of the inputs and replaces the old voltage values with new ones which is then transferred back to the CPU. Here's a diagram to make things more clear:
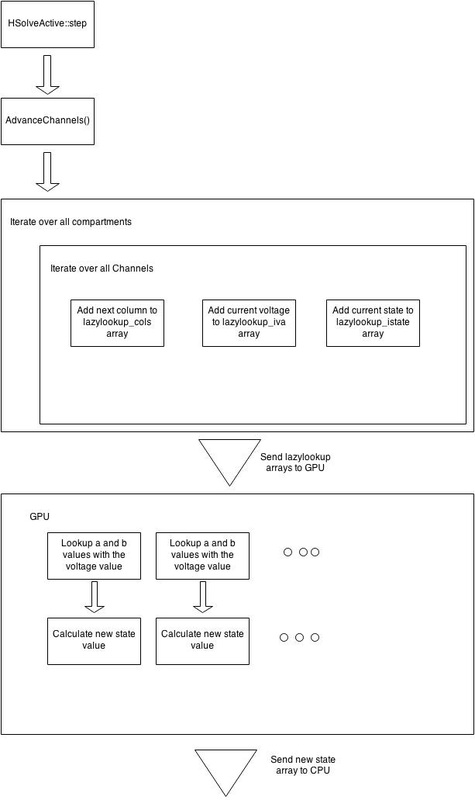
There are ofcourse a lot of optimizations that can be done on my implementation that I didn't have the time to get around to. The first, and most obvious, is to make use of the architectural flexibility provided in CUDA more effectively. Cuda allows users to spawn a bunch of blocks each of which have a set of threads running within them. The blocks share a common 'shared' memory which is faster than global memory and so, is highly recommended to be used as much as possible. In the current implementation, only 1 block is being spawned with all the threads. This is a rather inefficient implementation. A much better approach would be to assign a block for one type of channel. This will allow the lookup table of only that one channel to be stored on the shared memory of that block, allowing for much faster lookup times.
There is still a lot of work to be done in order to make the parallel algorithm provide the sort of speedup that is expected from GPUs. This is only a first attempt at parallelization.
There is still a lot of work to be done in order to make the parallel algorithm provide the sort of speedup that is expected from GPUs. This is only a first attempt at parallelization.
 RSS Feed
RSS Feed
