Trying to tackle the entirety of MOOSE directly wasn't working too well. So I am now working on parallelizing an example class. This can then be extended to HSolve where the GPU capabilities are actually required. This is a good exercising in understanding how to compile and run CUDA code alongside other CPU code, so I decided to document the entire process here.
The task I was given was simple - get a MOOSE class to calculate the sum of numbers from 1 upto some n, where n is defined by a member of that class. Then transfer the computation to the GPU while still maintaining an interface to MOOSE.
Setting up the MOOSE class
The example class I created is basically the same as the class I wrote about a few posts back. Do refer back to that post if you need a refresher on MOOSE classes.
The only change I made is in the process function. The class now calculates the sum of numbers from 1 upto y_ (one of its datamembers) and stores the result in x_ (another one of its datamembers). Heres the process function:
The only change I made is in the process function. The class now calculates the sum of numbers from 1 upto y_ (one of its datamembers) and stores the result in x_ (another one of its datamembers). Heres the process function:
void Example::process( const Eref& e, ProcPtr p )
{
int count = 0;
for (int i=1; i<y_; i++)
{
count += i;
}
x_ = count;
}
The rest of the class is the same as before.
Now the aim is to shift this computation to the GPU. Ofcourse, being a GPU, we need to also develop a parallel algorithm to calculate this sum instead of just iterating through the array and summing the numbers. Let's create a new project where all the GPU coding can be done and later work on integrating that code into this class.
Now the aim is to shift this computation to the GPU. Ofcourse, being a GPU, we need to also develop a parallel algorithm to calculate this sum instead of just iterating through the array and summing the numbers. Let's create a new project where all the GPU coding can be done and later work on integrating that code into this class.
The Parallel Reduce Algorithm
This section will focus on programming the GPU to calculate the sum of numbers from 1 to n.
NOTE: You need to have a working installation of CUDA for this part. If you don't have one, a number of tutorials exist to guide you through the installation process. Complete that before you continue.
Every CUDA program has two parts - the main section and the kernel. The main section runs on the host (most often the CPU). Code written here is almost identical to ordinary C++ code. The kernel is where all the magic happens. This code is loaded into the device (the GPU) and will be run once by each computational unit within the GPU.
So the idea is that all the control is at the hands of the CPU, where you would write ordinary C++ code to control flow of instructions, while the actual data processing is done at the GPU, which will typically have small snippets of C++ code and a small amount of local memory but will run the same code multiple times in parallel. Together, they make a formidable number crunching machine!
Let's first take a look at the CPU code
NOTE: You need to have a working installation of CUDA for this part. If you don't have one, a number of tutorials exist to guide you through the installation process. Complete that before you continue.
Every CUDA program has two parts - the main section and the kernel. The main section runs on the host (most often the CPU). Code written here is almost identical to ordinary C++ code. The kernel is where all the magic happens. This code is loaded into the device (the GPU) and will be run once by each computational unit within the GPU.
So the idea is that all the control is at the hands of the CPU, where you would write ordinary C++ code to control flow of instructions, while the actual data processing is done at the GPU, which will typically have small snippets of C++ code and a small amount of local memory but will run the same code multiple times in parallel. Together, they make a formidable number crunching machine!
Let's first take a look at the CPU code
int main()
{
int n[20] = {0};
int *n_d;
int y=20;
dim3 dimBlock( y, 1 );
dim3 dimGrid( 1, 1 );
const int asize = y*sizeof(int);
//1) Fill up the array with numbers from 1 to y
for (int i=0; i<y; i++)
n[i] = i;
//2) Allocate memory for the array on the GPU
cudaMalloc( (void**)&n_d, asize );
//3) Copy over the array from CPU to GPU
cudaMemcpy(n_d, n, asize, cudaMemcpyHostToDevice );
//4) Call the kernel
findSumToN<<<dimGrid, dimBlock>>>(n_d, y);
//5) Copy back the array from GPU to CPU
cudaMemcpy(n, n_d, asize, cudaMemcpyDeviceToHost);
//6) Free memory on the GPU
cudaFree (n_d);
std::cout << "\nSum: " << n[0]<< '\n';
return EXIT_SUCCESS;
}
The code is about as straightforward as you can imagine. Y is the limit until which we need to sum. In the unlikely case that the code isn't self explanatory, I have put down the steps here:
Let's take a look at some of the interesting aspects of this code.
NOTE: GPUs have a number of different levels of memory, each of which have specific tradeoffs between storage space and access speed. I haven't gone into those details here, but they are worth a read.
Before we look at the kernel, a brief introduction to the Parallel Reduce Algorithm will be helpful
- Generate the array having integers from 1 to y.
- Allocate memory on the GPU to hold the array.
- Copy the array from CPU to GPU.
- Call the kernel y times.
- Copy the array from GPU back to CPU.
- Free memory on the GPU.
Let's take a look at some of the interesting aspects of this code.
- The dimBlock and dimGrid definitions you see on top are a consequence of how computational units (CUs) are arranged in CUDA. The GPU contains a large number of computational units which are grouped together (in sets of 32, 64 etc) to form a block. Blocks are further grouped into a grid. CUDA also provides the helpful feature of identifying CUs within a block and blocks within a grid using 2 dimensional or even 3 dimensional coordinates. The actual arrangement in the GPU will be linear ofcourse, but this interface can be very helpful when dealing with applications in 2D space (like image processing) or 3D space(like point cloud analysis).
- cudaMalloc is the GPU equivalent to malloc. It allocates the specified space on the GPU and points the specified pointer to the start address. The name of the pointer is n_d. The CUDA convention is to append _d to all pointers that are pointing to memory on the device.
NOTE: GPUs have a number of different levels of memory, each of which have specific tradeoffs between storage space and access speed. I haven't gone into those details here, but they are worth a read.
- cudaMemcpy is again similar to memcpy, but does this between the CPU and GPU. Note that last parameter which determines which direction the memory is being copied.
- findSumToN is a function call to a function that we haven't yet defined. This is the kernel, and I will come to this in a moment. Before that, take a look at the triple less-than and greater-than signs. Between them is the dimGrid and dimBlock that we defined earlier. This determines the number of kernels that are launched. In our case, dimBlock is (y, 1), so y CUs will be launched per block. Since dimGrid is (1,1), only one block will be launched. So that is y CUs in total, all launched linearly, within the same block. This is ofcourse not the best way to parallelize since a block might only be able to launch 32 threads (based on the GPU hardware) and theres a good chance y will be more than that. Nevertheless, this is enough for this project.
- cudaFree, as you may imagine, just releases the memory pointed to by the pointer in its argument.
Before we look at the kernel, a brief introduction to the Parallel Reduce Algorithm will be helpful
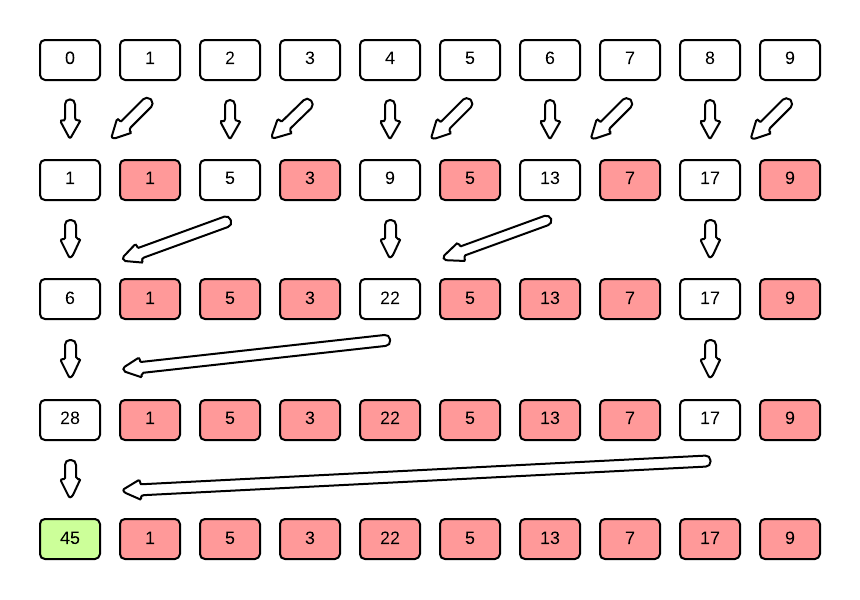
What you see above is the reduce algorithm used with addition in its entirety!
The naive way of adding the numbers in an array is ofourse to take one element (usually the first) and keep adding each of the other elements to it until all the elements have been added. The resulting array will have the sum of numbers in it's first cell.
Here, the end result is the same, but the method is slightly different. We first take all even elements (every second element starting from the first) and add the element immediately after it. We then take every fourth element and add the element two spaces away. Then eighth, and so on until all the elements have been added.
The great thing about this approach is that it is far more parallelizable than the naive approach. To understand why, take a look at the first set of additions. Each addition takes 2 elements from the first array and puts the result into one element of the second array. None of those additions depend on values computed by any other operation. So all of them can be computed in parallel. The summation will have to pause after that first step though, to make sure all parallel units have finished computed the first level of summation before the next level of summation can be performed. This is called a synchronisation of threads.
So what will this look like in parallel code?
The naive way of adding the numbers in an array is ofourse to take one element (usually the first) and keep adding each of the other elements to it until all the elements have been added. The resulting array will have the sum of numbers in it's first cell.
Here, the end result is the same, but the method is slightly different. We first take all even elements (every second element starting from the first) and add the element immediately after it. We then take every fourth element and add the element two spaces away. Then eighth, and so on until all the elements have been added.
The great thing about this approach is that it is far more parallelizable than the naive approach. To understand why, take a look at the first set of additions. Each addition takes 2 elements from the first array and puts the result into one element of the second array. None of those additions depend on values computed by any other operation. So all of them can be computed in parallel. The summation will have to pause after that first step though, to make sure all parallel units have finished computed the first level of summation before the next level of summation can be performed. This is called a synchronisation of threads.
So what will this look like in parallel code?
int tId = threadIdx.x;
if (tId%2 == 0)
n[tId] += n[tId+1];
__syncthreads();
if (tId%4 == 0)
n[tId] += n[tId+2];
__syncthreads();
if (tId%8 == 0)
n[tId] += n[tId+4];
__syncthreads();
if (tId%16 == 0)
n[tId] += n[tId+8];
Here, tId is the ID number of the thread being run. Remember how we started y computational units in that call to findSumToN? This is (a simplified version of) the code that they will run. Each of the y CUs are given a unique thread number which is used to identify them in the code.
So what exactly is happening here? All threads with odd tId will actually do nothing! This is a waste of CUs and should be avoided in production code. All threads with tId a factor of 2 will enter the first if branch. Here, they will compute the sum of the array element n[tId] and the element immediately after it. The __syncthreads() command instructs the GPU to force all CUs to wait until all other CUs have reached the same point. This will ensure that all the first level of calculations have been done, as mentioned before.
Then, all threads whose tIds are factors of 4 enter the second if branch where they add their element with the element two spaces away. This continues onward.
I have converted all of this into a generic function shown below:
So what exactly is happening here? All threads with odd tId will actually do nothing! This is a waste of CUs and should be avoided in production code. All threads with tId a factor of 2 will enter the first if branch. Here, they will compute the sum of the array element n[tId] and the element immediately after it. The __syncthreads() command instructs the GPU to force all CUs to wait until all other CUs have reached the same point. This will ensure that all the first level of calculations have been done, as mentioned before.
Then, all threads whose tIds are factors of 4 enter the second if branch where they add their element with the element two spaces away. This continues onward.
I have converted all of this into a generic function shown below:
__global__
void findSumToN(int *n, int limit)
{
int tId = threadIdx.x;
for (int i=0; i<=(int)log2((double)limit); i++)
{
if (tId%(int)(pow(2.0,(double)(i+1))) == 0){
if (tId+(int)pow(2.0, (double)i) >= limit) break;
n[tId] += n[tId+(int)pow(2.0, (double)i)];
}
__syncthreads();
}
}
Note that this is far from optimised code! There are way more calls to math functions than are required and many threads will be severely underused. It is, however, a fairly simple example to understand.
I originally planned to put down the entire process of making the GpuSolver class and integrating it into MOOSE over here, but this is becoming a very long post. So I'll stop here and finish it in the next post.
 RSS Feed
RSS Feed
